核心模型:并行扩散生成
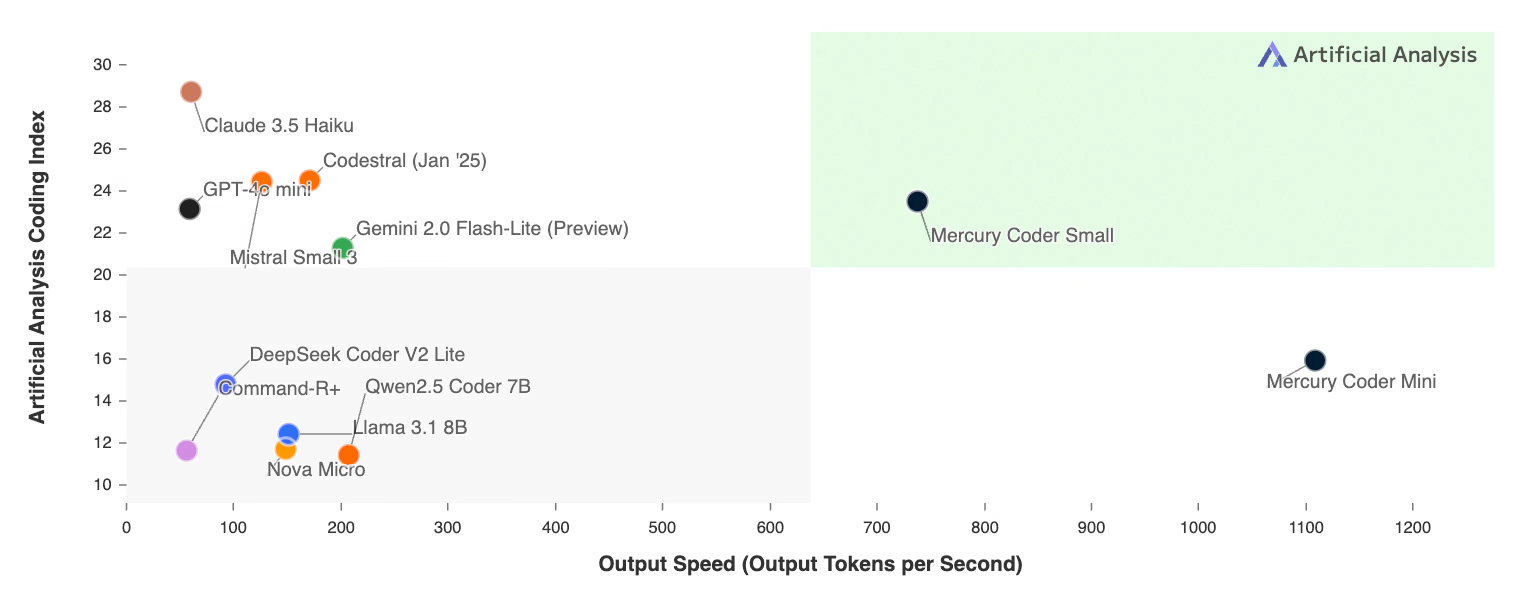
Mercury Coder 基于自研扩散 Transformer 架构,一次可并行生成多个 token,提升吞吐率并降低延迟,最大可支持 10 万 token 文档上下文。
向下滑动
↓
基于扩散语言模型(dLLM),比传统大模型快 5–10 倍,响应仅需 150 毫秒,代码输出更准确,支持企业级 API 接入与本地部署。
Mercury Coder 基于自研扩散 Transformer 架构,一次可并行生成多个 token,提升吞吐率并降低延迟,最大可支持 10 万 token 文档上下文。
兼容 OpenAI 标准 API,支持流式输出、云端托管与私有部署。已集成至 Poe 与 NLWeb,可与现有代码工具链无缝对接。
专有推理引擎优化 GPU 并行效率,支持动态批处理。通过 SOC2 认证,多租户隔离机制保障企业安全。
适用于代码助手、对话编程、自动化代理系统、语音交互、长文档处理等高频响应需求场景。
Mercury 在响应速度、吞吐量、上下文长度上全面领先,适合对实时性能要求高的企业及开发者。
总部位于硅谷,由斯坦福、UCLA、康奈尔等 AI 教授联合创办,聚焦构建下一代 AI 基础设施。